
Una guía paso a paso para crear en Python el gráfico actualizado de desigualdad e ingreso de Colombia
TUTORIALES
Jhonnathan Zambrano
6 min read
En esta entrada vamos a replicar el gráfico 1 del “World Inequality Report 2022” para el caso de Colombia. Lo primero que hay que hacer es descargar el archivo que queremos, y subirlo a nuestro github. Para ello, vamos al perfil de Colombia en WID y damos a descargar base de datos completa
Jhonnathan Zambrano · 3/03/2024



Aquí obtendremos un archivo .zip, de donde extraeremos “WID_data_CO.csv”
Lo puedes subir a tu propio repositorio en github, o utilizar el que acabo de crear: Ahora, nos vamos a Google Colab para trabajar. El cuaderno de Google Colab que seguiré lo puedes consultar aquí :
Debemos importar el archivo. Por lo cual, importamos primero la librería pandas, definimos el objeto url; y, lo leemos para crear el data-frame, con la salvedad que los separadores son ";"
Finalmente, comprobamos con “df.head()” que todo se importó adecuadamente
import pandas as pd
url=("https://raw.githubusercontent.com/zambranojazu/Inequality-Co/main/WID_data_CO.csv")
df=pd.read_csv(url, sep=";")
df.head()
Nota: el código del notebook (sin anotaciones) se puede encontrar en:
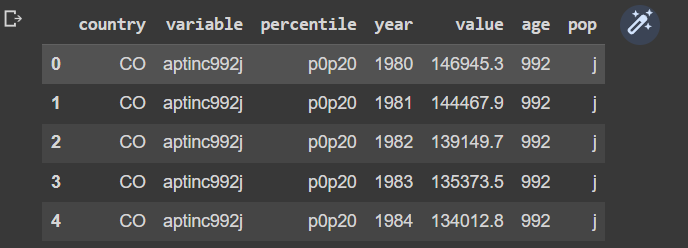
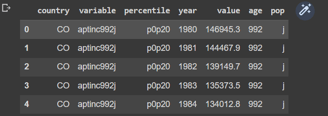
Lo siguiente que debemos hacer es encontrar la variable codificada que contiene la información requerida. Para ello, observamos el documento técnico de los datos el cual menciona:
pd.options.display.max_rows= None
pd.value_counts (df['year'])
Una vez que conocemos la organización de la información, hacemos el plan para filtrar los datos que necesitamos:
Para obtener la distribución del ingreso del 50% más pobre: hay que obtener la variable “sptinc992j”, el percentil “p0p50”, y el año “2021”
Para obtener la distribución del ingreso del 40% intermedio: hay que obtener la variable “sptinc992j”; sumar los percentiles “p30p40” + “p40p50”+ “p50p60” +” p60p70”; y el año “2021”
Para obtener la distribución del ingreso para el 10% más rico: hay que obtener la variable “sptinc992j”, el percentil “p90p100”, y el año “2021”
Para obtener la distribución del ingreso para el 1% más rico: hay que obtener la variable “sptinc992j”, el percentil “p99.1p100”, y el año “2021”
El proceso se repite de igual manera para la variable “shwealj992”. Para mayor información acerca de la utilidad de cada una de las se dejará la explicación de las diferentes funciones en el notebook de Google colab por medio del carácter #.
El código para el caso de los ingresos sería:
a. Porcentaje del ingreso para el 50% más pobre
analisis="sptinc992j"
porcentaje=df[(df['variable']==analisis) & (df['percentile']=="p0p50") & (df['year']==2021)]
y1s=porcentaje['value'].values
y1=y1s[0]
b. cálculo del 40% intermedio
porcentaje=df[(df['variable']==analisis) & (df['percentile'].isin(["p40p50", "p50p60","p60p70","p70p80"])) & (df['year']==2021)]
y2s=porcentaje['value'].values
y2=y2s.sum()
c. calculos del 10%más ricos
porcentaje=df[(df['variable']==analisis) & (df['percentile']=="p90p100") & (df['year']==2021)]
y3s=porcentaje['value'].values
y3=y3s[0]
El código para el caso de la riqueza (con el mismo procedimiento) es:
analisis="shweal992j"
#50% más pobre
porcentaje=df[(df['variable']==analisis) & (df['percentile']=="p0p50") & (df['year']==2021)]
w1s=porcentaje['value'].values
w1=w1s[0]
#40% intermedio
porcentaje=df[(df['variable']==analisis) & (df['percentile'].isin(["p40p50", "p50p60","p60p70","p70p80"])) & (df['year']==2021)]
w2s=porcentaje['value'].values
w2=w2s.sum()
#10% más rico
porcentaje=df[(df['variable']==analisis) & (df['percentile']=="p90p100") & (df['year']==2021)]
w3s=porcentaje['value'].values
w3=w3s[0]
#1%más rico
porcentaje=df[(df['variable']==analisis) & (df['percentile']=="p99.1p100") & (df['year']==2021)]
w4s=porcentaje['value'].values
w4=w4s[0]
Los datos que obtenemos son:
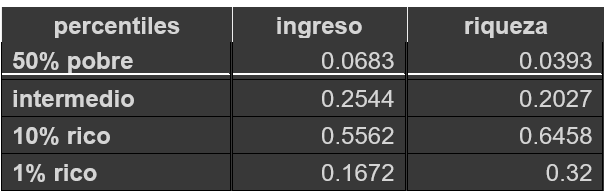
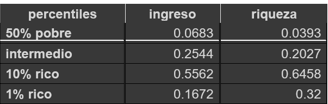
Esta tabla se logró por medio de la organización de datos en un dataframe:
mydict={'percentiles':['50% pobre', 'intermedio',
'10% rico', '1% rico'],
'ingreso':[y1, y2, y3, y4],
'riqueza':[w1, w2, w3, w4]}
df1 = pd.DataFrame(mydict).set_index('percentiles')
df1.head()
Una vez que tenemos los datos ya depurados, podemos realizar la gráfica respectiva. En este caso, utilizamos las características que nos permite matplotlib.pyplot y matplotlib.patches, para escribir lo siguiente:
#variables y datos
percentiles=["50% pobre", "intermedio", "10% rico", "1% rico"]
ingreso=[y1, y2, y3, y4]
riqueza=[w1, w2, w3, w4]
colores=["b", "lightgreen", "r", "c"]
#eje x (co), ancho (an)
co=np.arange(len(percentiles))
an=0.7
#espacio (fig), definición de eje y (ingreso, riqueza)
fig, ax=plt.subplots()
ax.bar (co, ingreso, an, color= colores)
ax.bar (co+5.9, riqueza, an, color=colores)
#valores sobre las barras
for i, j in zip(co, ingreso):
ax.annotate(j, xy=(i-0.5, j+0.05))
for i, j in zip(co, riqueza):
ax.annotate(j, xy=(i+5.5, j+0.005))
#letreros: títulos y labels
ax.set_title('Desigualdad de ingresos y riqueza en Colombia 2021')
ax.set_ylabel('Porcentaje de ingreso y riqueza total')
#leyendas que no están en los ejes
pobre=mpatches.Patch(color='b', label='50% más pobre')
medio=mpatches.Patch(color='lightgreen', label='40% intermedio')
diezrico=mpatches.Patch(color='r', label='10% más rico')
unorico=mpatches.Patch(color='c', label='1% más rico')
plt.legend(handles=[pobre, medio, diezrico, unorico], loc=(1.05,0.4), fancybox=True) #localización, y borde redondeado
plt.show()
#letreros eje x
plt.xticks([1.5,7.8], ["Ingreso", "Riqueza"])
El resultado final es una gráfica de desigualdad de ingreso y desigualdad de riqueza, tal que:
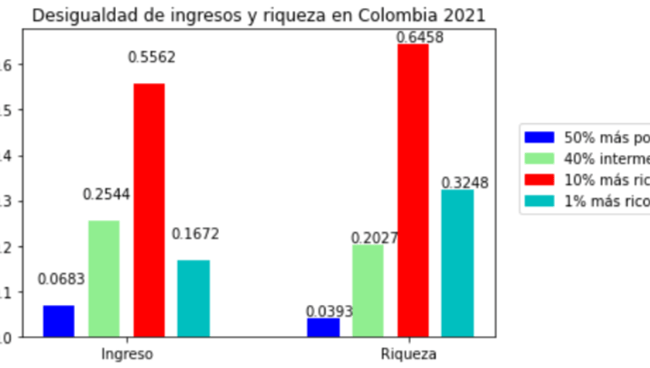
Una vez terminado el gráfico ya podemos iniciar el análisis económico
Entrada de análisis
Gráfica 1. Desigualdad mundial de ingreso y de riqueza, 2021
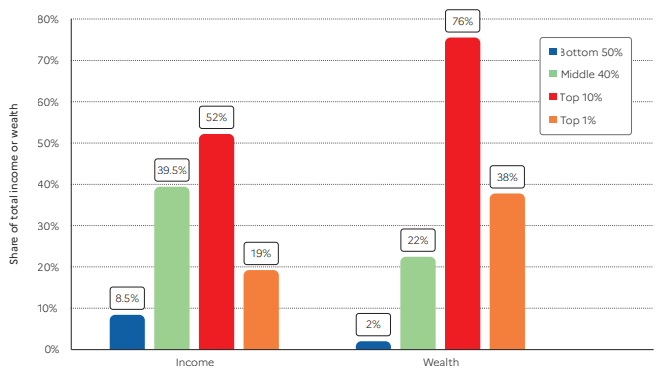
Gráfica 2. Desigualdad nacional de ingreso y de riqueza, 2021
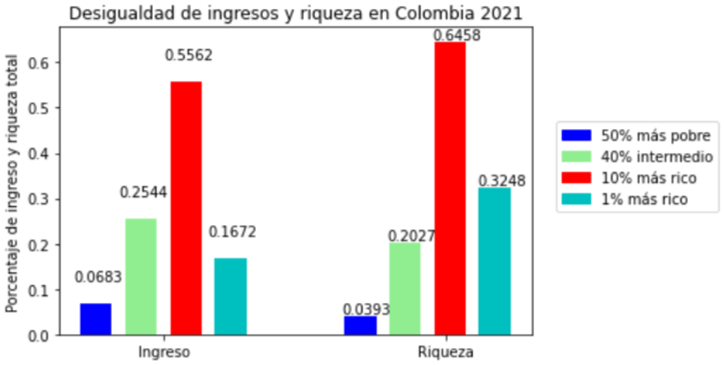
La inequidad del ingreso es medida usando la distribución del ingreso nacional antes de impuestos entre los adultos (serie dividida en partes iguales). La renta nacional antes de impuestos es la suma de todos los flujos de renta personal antes de impuestos que se acumulan para los propietarios de los factores de producción, el trabajo y el capital, incluidas las prestaciones de seguridad social, pero excluyendo otras formas de redistribución (impuesto sobre la renta, beneficios de asistencia social, etc.)
La inequidad de la riqueza es medida usando la distribución de la riqueza neta de los hogares entre los adultos (serie divida en partes iguales). El patrimonio neto de los hogares es la suma de los activos financieros (p.e. acciones o bonos) y los activos no financieros (p.e. viviendas o terrenos) de propiedad de las personas, netas de sus deudas
La desigualdad en nuestro país sigue el dibujo mundial: un 10% de la población tiene más ingresos que el 50% de los más pobres y el 40% de los percentiles intermedios
Adicional a ello, este 10% de ricos (barra roja) tiene una mayor participación en los cálculos de la riqueza, y menos en los de los ingresos. Lo cual implica que los percentiles bajos (barra azul) y medios (barra verde) retroceden en su participación (al pasar del análisis de ingresos al de la riqueza).
Ahora bien, tomando esta información, las variables que corresponden a dicha descripción en el documento “WID_meatadata_CO.csv” son:
Inequidad del ingreso medido como una proporción (share): sptinc992j,
Inequidad de la riqueza de los hogares como proporción (share): shwealj992
Analizamos cuáles son los atributos que poseemos en las columnas “percentile”, “year” y “age”, con lo cual, en el código configuramos, primero, que el Google Colab nos muestre una consulta completa (sin puntos suspensivos); y luego, para ver los atributos, contamos los valores de las columnas solicitadas (“percenile”, “year”, “age”).
Referencias bibliográficas
Consulta el perfil de Colombia en: https://wid.world/es/country/es-colombia/
Descarga el archivo csv en: https://github.com/zambranojazu/Inequality-Co/blob/main/WID_data_CO.csv
Puedes acceder al cuaderno en: https://colab.research.google.com/drive/1xGw2EYvItcuJOWCOORwF6tKEBhrM8Fiu?usp=sharing
Puedes acceder al cuaderno en: https://colab.research.google.com/drive/1psAUnnnJdAbMEv6puYkJIjFamkybac-k?usp=sharing
Datos tomados de https://wir2022.wid.world/www-site/uploads/2021/12/WIR2022-Technical-Note-Figures-Tables-1.pdf